Confession time
This started off with me reading a blurb in the release notes about SQL Server 2016 CTP 3.3. The blurb in question is about statistics. They’re so cool! Do they get fragmented? NO! Stop trying to defragment them, you little monkey.
Autostats improvements in CTP 3.3
Previously, statistics were automatically recalculated when the change exceeded a fixed threshold. As of CTP 3.3, we have refined the algorithm such that it is no longer a fixed threshold, but in general will be more aggressive in triggering statistics scans, resulting in more accurate query plans.
I got unnaturally excited about this, because it sounds like the behavior of Trace Flag 2371. Anyone who has taken a bite out of a terabyte database probably knows about this one. Ever try waiting for statistics to automatically update on a billion row table? You’re gonna need a crate of Snickers bars. I’m still going to write about the 2016 stuff, but I caught something weird when I was working on a way to demonstrate those thresholds. And that something was how SQL tracks modifications to unique indexes. It freaked me out for, like, days.
We’re gonna need a couple tables
But they’ll be slightly different. It’s the only way to really show you how weird it gets inside SQL’s head.
Table 1 has a clustered PK on the ID column. It has a non-unique, nonclustered index on DateFiller and TextFiller.
IF OBJECT_ID('[dbo].[Nuisance]') IS NOT NULL
DROP TABLE [dbo].[Nuisance];
GO
CREATE TABLE [dbo].[Nuisance]
(
[ID] BIGINT NOT NULL ,
[DateFiller] DATETIME2 DEFAULT SYSDATETIME() NOT NULL ,
[TextFiller] VARCHAR(10) DEFAULT 'A' NOT NULL
);
ALTER TABLE [dbo].[Nuisance] ADD CONSTRAINT [PK_Nuisance] PRIMARY KEY CLUSTERED ([ID]);
CREATE NONCLUSTERED INDEX [ix_Nuisance] ON [dbo].[Nuisance] ([DateFiller], [TextFiller])
Table 2 has the same structure, but the clustered PK is on ID and DateFiller. Same nonclustered index, though.
IF OBJECT_ID('[dbo].[Nuisance2]') IS NOT NULL
DROP TABLE [dbo].[Nuisance2];
GO
CREATE TABLE [dbo].[Nuisance2]
(
[ID] BIGINT NOT NULL ,
[DateFiller] DATETIME2 DEFAULT SYSDATETIME() NOT NULL ,
[TextFiller] VARCHAR(10) DEFAULT 'A' NOT NULL
);
ALTER TABLE [dbo].[Nuisance2] ADD CONSTRAINT [PK_Nuisance2] PRIMARY KEY CLUSTERED ([ID], [DateFiller]);
CREATE NONCLUSTERED INDEX [ix_Nuisance2] ON [dbo].[Nuisance2] ([DateFiller], [TextFiller])
All this code works, I swear. Let’s drop a million rows into each.
INSERT [dbo].[Nuisance] WITH ( TABLOCK )
( [ID] ,
[DateFiller] ,
[TextFiller] )
SELECT TOP 1000000
ROW_NUMBER() OVER ( ORDER BY ( SELECT NULL ) ) ,
DATEADD(SECOND, [sm1].[message_id], SYSDATETIME()) ,
SUBSTRING([sm1].[text], 0, 9)
FROM
[sys].[messages] AS [sm1] ,
[sys].[messages] AS [sm2] ,
[sys].[messages] AS [sm3];
INSERT [dbo].[Nuisance2] WITH ( TABLOCK )
( [ID] ,
[DateFiller] ,
[TextFiller] )
SELECT TOP 1000000
ROW_NUMBER() OVER ( ORDER BY ( SELECT NULL ) ) ,
DATEADD(SECOND, [sm1].[message_id], SYSDATETIME()) ,
SUBSTRING([sm1].[text], 0, 9)
FROM
[sys].[messages] AS [sm1] ,
[sys].[messages] AS [sm2] ,
[sys].[messages] AS [sm3];
Now let’s take a basic look at what’s going on in our indexes and statistics. We just created tables! And inserted a million rows! Each! That has to count for something, right? Here’s a query to check that kind of thing.
SELECT
[t].[name] AS [table_name] ,
[si].[name] AS [index_name] ,
[si].[dpages] AS [data_pages] ,
[si].[rowcnt] AS [index_row_count] ,
[si].[rows] AS [index_rows] ,
[ddsp].[rows] AS [stats_rows] ,
[ddsp].[rows_sampled] AS [stats_rows_sampled] ,
[si].[rowmodctr] AS [index_row_modifications] ,
[ddsp].[modification_counter] AS [stats_modification_counter] ,
[ddsp].[last_updated] AS [last_stats_update]
FROM
[sys].[sysindexes] [si]
JOIN [sys].[stats] [s]
ON [si].[id] = [s].[object_id]
AND [si].[indid] = [s].[stats_id]
JOIN [sys].[tables] [t]
ON [t].[object_id] = [si].[id]
CROSS APPLY [sys].[dm_db_stats_properties]([s].[object_id], [s].[stats_id]) AS [ddsp]
WHERE
[t].[name] LIKE 'Nuisance%'
ORDER BY
[t].[name] ,
[si].[indid];
Holy heck why don’t we have any statistics? The indexes tracked our million modifications from the insert, but the statistics aren’t showing us anything. They’re all NULL! Right now, SQL has no idea what’s going on in here.
![Empty inside]()
Empty inside
At least, until it has to. If we ran a query with a WHERE clause, an initial statistics update would fire off. Hooray. SQL is lazy. We can skip all that fuss and just update manually. I want a FULLSCAN! No fullscan, no peace. Or something.
UPDATE STATISTICS [dbo].[Nuisance] WITH FULLSCAN;
UPDATE STATISTICS [dbo].[Nuisance2] WITH FULLSCAN;
If we go back to our DMV query, the stats columns will at least not be NULL now. It will show 1,000,000 rows sampled, and no modifications, and the last stats update column will have a date in it. Wonderful. You don’t need a picture of that. Conceptualize. Channel your inner artist.
Weir it all gets whered
Let’s think back to our indexes.
- Nuisance has the clustered PK on ID
- Nuisance2 has the clustered PK on ID, DateFiller
- They both have non-unique nonclustered indexes on DateFiller, TextFiller
One may posit, then, that they could let their workloads run wild and free, and that SQL would dutifully track modifications, and trigger automatic updates when necessary. This is being run on 2014, so we don’t expect the dynamic threshold stuff. The rule that applies to us here, since our table is >500 rows, is that if 20% of the table + 500 rows changes, SQL will consider the statistics stale, and trigger an update the next time a query runs against the table, and uses those statistics.
But, but, but! It does not treat all modifications equally. Let’s look at some examples, and then buckle in for the explanation. No TL;DR here. You must all suffer as I have suffered.
We’ll start with an update of the nonclustered index on Nuisance.
UPDATE
[n]
SET
[n].[DateFiller] = DATEADD(MICROSECOND, 1, [n].[DateFiller]),
[n].[TextFiller] = REPLACE(n.[TextFiller], ' ', '')
FROM
[dbo].[Nuisance] AS [n]
WHERE
[n].[ID] >= 1 AND ID <= 100000
AND
[n].[DateFiller] >= '0001-01-01' AND [n].[DateFiller] <= '9999-12-31'
SELECT @@ROWCOUNT AS [Rows Modified]
We use @@ROWCOUNT to verify the number of rows that were updated in the query. Got it? Good. It should show you that 100,000 rows were harmed during the filming of that query. Poor rows.
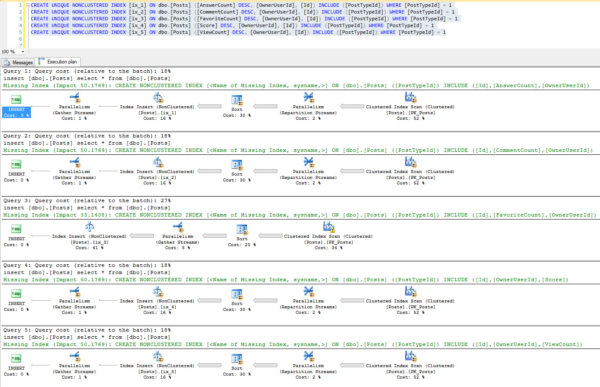
Here’s the execution plan for it. Since we don’t have a kajillion indexes on the table, we get a narrow plan. There are some compute scalars to come up with the date adding, the replace, and the predicates in our WHERE clause. It’s all in the book. You should get the book.
![ACTUAL EXE-CUTIE-PIE]()
ACTUAL EXE-CUTIE-PIE
At this point, if you run the DMV query, you should see 100,000 modifications to the nonclustered index on Nuisance. Not enough to trigger an update, but we don’t care about that in this post. It makes sense though, right? We updated 100k rows, SQL tracked 100k modifications.
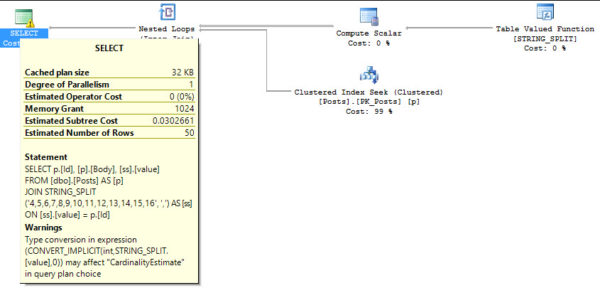
What if we run the same update on Nuisance2? We still only update 100k rows, but our execution plan changes a little bit…
![Split! Sort! Collapse! Fear! Fire! Foes!]()
Split! Sort! Collapse! Fear! Fire! Foes!
And now we have TWO HUNDRED THOUSAND MODIFICATIONS?
![What in the wide world of sports?]()
What in the wide world of sports?
This is how SQL handles updates on columns with unique constraints, which we’ll get to. But let’s look at a couple other updates first!
UPDATE
[n]
SET
[n].[ID] += 1
FROM
[dbo].[Nuisance] AS [n]
SELECT @@ROWCOUNT AS [Rows Modified]
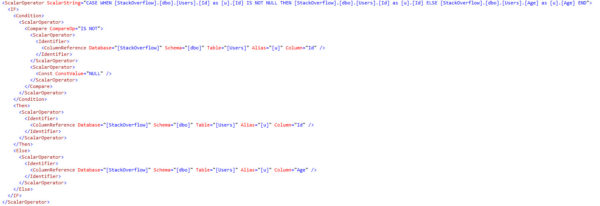
If we go back and update just the ID column of Nuisance, something really cool happens.
![Two is the loneliest number]()
Two is the loneliest number
It only took two modifications to update one million rows in the clustered index. We still had to update all million rows of the nonclustered index (+1, I’m guessing, to insert the new row for ID 1,000,001).
That’s because, if you’ve been paying attention, nonclustered indexes carry all the key columns of your clustered index. We updated the clustered index, so we had to update our nonclustered index. If we had multiple nonclustered indexes, we’d have to update them all. This is why many sane and rational people will tell you to not pick columns you’re going to update for your clustered index.
If you’re still looking at execution plans, you’ll see the split/sort/collapse operators going into the clustered index again, but only split and sort going into the nonclustered index update.
![Oh, yeah. That update.]()
Oh, yeah. That update.
If we run the same update on Nuisance2, and check back in on the DMVs, it took a million modifications (+5 this time; due to the data distribution, there are net 5 new rows, since there are exactly five unique values in DateFiller). But at least it didn’t take 2 million modifications to update it, right?
![I still can't do math.]()
I still can’t do math.
Bring it on home
Why are there such big differences in the modification counts?
For the update to the ID column of Nuisance, it only took two modifications. This is because of the split/sort/collapse operations.
Split takes the update, and, as the name implies, splits it into inserts and deletes. If you think about what it would look like to change 1 through 1,000,000 to 2 through 1,000,001, it really is only two modifications:
- Delete row 1
- Insert row 1,000,001
All the other numbers in the range already exist, in order. That’s what the sort does, basically. Orders the values, and whether they need an insert or a delete to occur. The final operation, collapse, removes duplicate actions. You don’t need to delete and re-insert every number.
Unfortunately, for Nuisance2, it results in doubling the modifications required. This is true for the clustered index update, where DateFiller is the second column, and the nonclustered index update, where DateFiller is the leading column.
It doesn’t appear to be the data distribution, or the data type of the column that causes the double working. As things stand in this demo, there are only five unique values in DateFiller. I tried where it was all unique, I also tried it as DATE, and BIGINT, but in each scenario, SQL tracked 2x the number of modifications to each index.
Takeaways
I’m all for unique indexes! I’m even okay with two column PK/clustered indexes. But be really careful when assigning constraints, and make sure you test your workload against them. While they may obviously help read queries, there’s some cost to maintaining them when modifying data.
What I didn’t mention this whole time, because I didn’t want it to get in the way up there, was how long each update query took. So I’ll leave you with the statistics time and IO results for each one.
Thanks for reading!
Nuisance nonclustered index update
/*
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 3 ms.
Table 'Nuisance'. Scan count 1, logical reads 630970, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1062 ms, elapsed time = 1129 ms.
*/
Nuisance2 nonclustered index update
/*
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 2 ms.
Table 'Nuisance2'. Scan count 5, logical reads 1231177, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 2484 ms, elapsed time = 2633 ms.
*/
Nuisance clustered index update
/*
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 1 ms.
Table 'Nuisance'. Scan count 1, logical reads 9191793, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 20625 ms, elapsed time = 20622 ms.
*/
Nuisance2 clustered index update
/*
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 1 ms, elapsed time = 1 ms.
Table 'Nuisance2'. Scan count 1, logical reads 12191808, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 36141 ms, elapsed time = 36434 ms.
*/
Brent says: go back and read this again, because you didn’t digest it the first time. Plus, trust me, the time it takes you to read is nowhere near what it took for Erik to get to the root cause on this. (We saw the play-by-play unfold in the company chat room.)














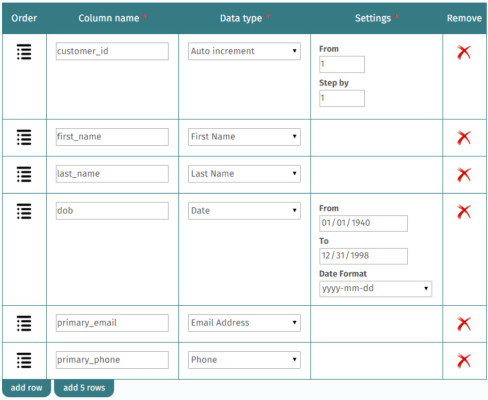
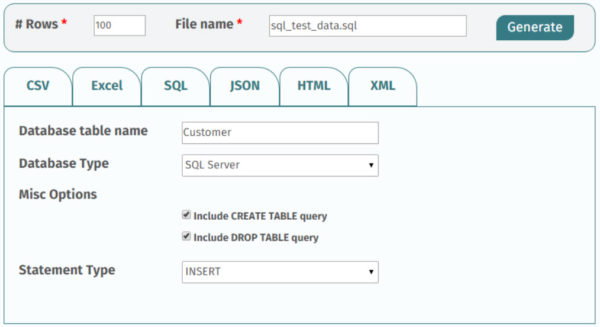
 Seriously, I love this thing. Not just because many of the databases I worked with under the software were hundreds of gigs, on up to 9 terabytes, but because the people behind the software really do care about the product. The customer support is aces (Hello, Pod One), and the developers are super helpful and responsive.
Seriously, I love this thing. Not just because many of the databases I worked with under the software were hundreds of gigs, on up to 9 terabytes, but because the people behind the software really do care about the product. The customer support is aces (Hello, Pod One), and the developers are super helpful and responsive.