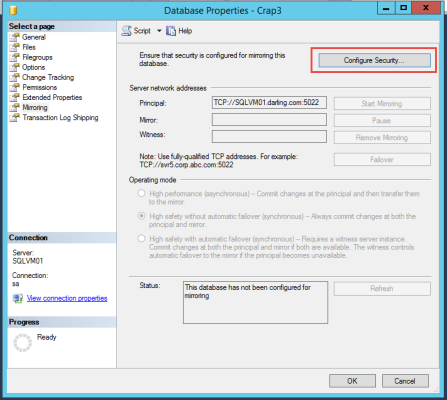
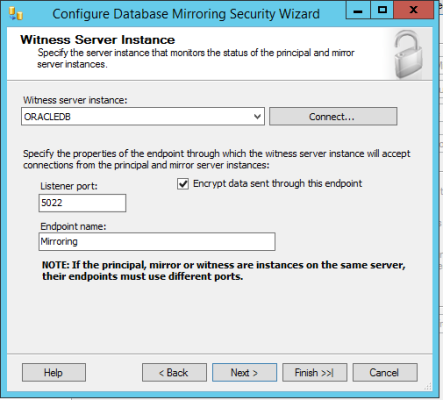
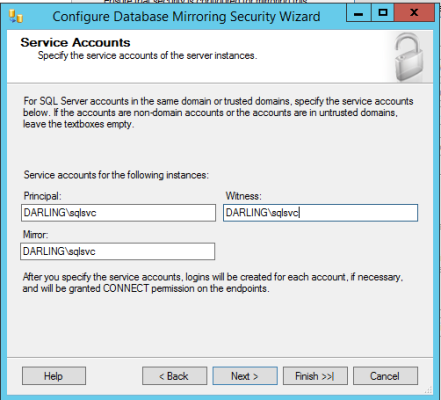
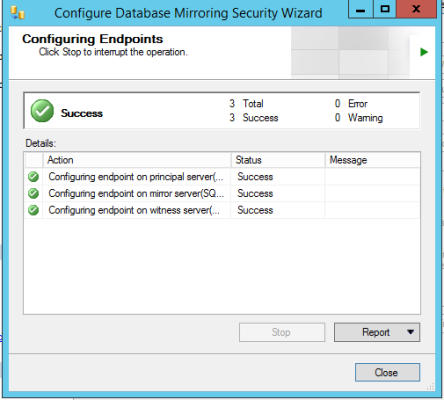
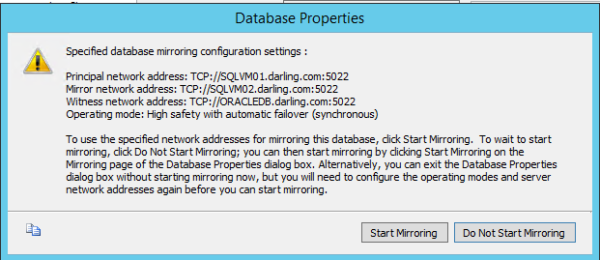
The almighty string
It’s so good for holding all sorts of things. Chicken roulade, beef roulade, salmon roulade. It’s also the way you should store phone numbers. If I could go back in time to when I first started working with SQL, that’s what I’d tell myself. Stop. Just, please, for the love of Codd, STOP TRYING TO STORE PHONE NUMBERS AS INTEGERS. It will only end in heartbreak and weird exponential notation.
But we’re here to talk about Oracle. And strings. And stuff you can do with them. I spent one Christmas writing a text parser that my wife still brings up when we go shopping. So this is an important area to me.
First things first, man
Oracle ships with a function to put your strings in proper case. It sounds trivial to most people, until you look at the amount of time, energy, and forum posts that have gone into getting the same behavior out of SQL Server. Why this isn’t built in is beyond me. I guess we really needed CHOOSE and IIF instead. Those are super helpful. Game changers, the both.
But check this out!
SELECT
INITCAP('BRENT OZAR UNLIMITED'),
INITCAP('brent ozar unlimited'),
INITCAP('BrEnT oZaR uNlImItEd')
FROM DUAL;
![I LOVE YOU ALL CAPS]()
I LOVE YOU ALL CAPS
But it doesn’t end there! I’m going to skip over the CONCAT function, because it only takes two arguments. In a situation where you need to do something like ‘Last Name, First Name’ you have to concatenate the comma + space to the last name. I think you actually end up typing more than just writing the whole thing out. So how do you do that?
SELECT HR.FIRST_NAME, HR.LAST_NAME, HR.LAST_NAME || ', ' || HR.FIRST_NAME AS "FULL_NAME"
FROM HR.EMPLOYEES HR;
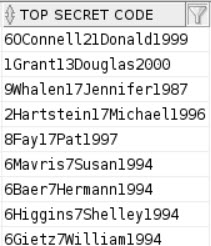
You use the double pipes (||) to tell Oracle to mush everything together. A slightly more complicated example is if you needed to generate a ‘password’ based on some different bits of data.
SELECT
EXTRACT(MONTH FROM HR.HIRE_DATE) ||
HR.LAST_NAME ||
EXTRACT(DAY FROM HR.HIRE_DATE) ||
HR.FIRST_NAME ||
EXTRACT(YEAR FROM HIRE_DATE) AS "TOP SECRET CODE"
FROM HR.EMPLOYEES HR;
Oracle is nice enough to let you put it all together without whinging about data types:
![Hint: don't actually generate passwords like this.]()
Hint: don’t actually generate passwords like this.
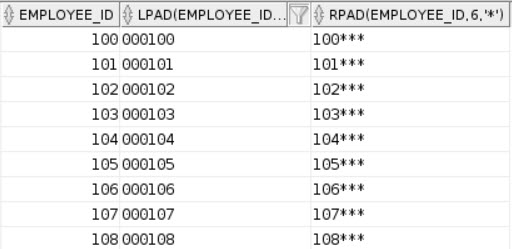
Oracle also has easy ways to pad strings, using LPAD and RPAD. This beats out most methods I’ve seen in SQL Server, using RIGHT/LEFT and some concatenation inside. It’s another situation where if you mix data types, the conversion happens automatically.
SELECT EMPLOYEE_ID,
LPAD(EMPLOYEE_ID, 6, 0), --Padding with zero
RPAD(EMPLOYEE_ID, 6, '*') --Padding with asterisk
FROM HR.EMPLOYEES HR;
What you get is about as expected: strings padded to 6 digits with the character of your choosing.
![Rubber Room]()
Rubber Room
SQL offers RTRIM and LTRIM to remove leading and trailing spaces from strings. If you need to remove other stuff, you have an additional step of replacing them, or calculating substrings. Oracle’s TRIM function gives you several different ways to have it operate. Oracle also has REPLACE, but whatever. It does what you think it does.
SELECT
' ' || PHONE_NUMBER || ' ' AS "PHONE WITH SPACES",
TRIM(' ' || PHONE_NUMBER || ' ') AS "PHONE WITH SPACES REMOVED",
TRIM(TRAILING '6' FROM PHONE_NUMBER) AS "TRAILING 6S REMOVED",
TRIM(LEADING '6' FROM PHONE_NUMBER) "LEADING 6 REMOVED",
TRIM(BOTH '6' FROM PHONE_NUMBER) AS "LEADING AND TRAILING REMOVED"
FROM HR.EMPLOYEES
WHERE PHONE_NUMBER = '603.123.6666';
TRIM by itself will remove trailing and leading spaces. You can also hint it to only do trailing, leading, or both, and additionally specify which character you want to remove. In the example above. I found a phone number that started with a 6 and ended with four 6s. Below is how each run of the TRIM function worked:
![Several Sixes]()
Several Sixes
It’s much more flexible and useful than SQL Server’s trimming functions, because it can be used to trim off things other than spaces.
Second String
Oracle has a really cool function for searching in strings, cleverly titled INSTR. It takes a few arguments, and sort of like CHARINDEX, you can tell it where in the string to start searching. The real magic for me is that you can also specify which OCCURRENCE of the string you want to find. The only downside is that it appears to be case sensitive.
SELECT LAST_NAME,
INSTR(LAST_NAME, 'A'), --First A
INSTR(LAST_NAME, 'A', 1, 2) --Second occurrence of A starting at first char
FROM HR.EMPLOYEES;
That runs, but it only gets us a hit for people whose names start with A:
![A is for Ack]()
A is for Ack
All those B names have an a for the second character. But it’s easy to solve though, just use the UPPER function (or LOWER, whatever).
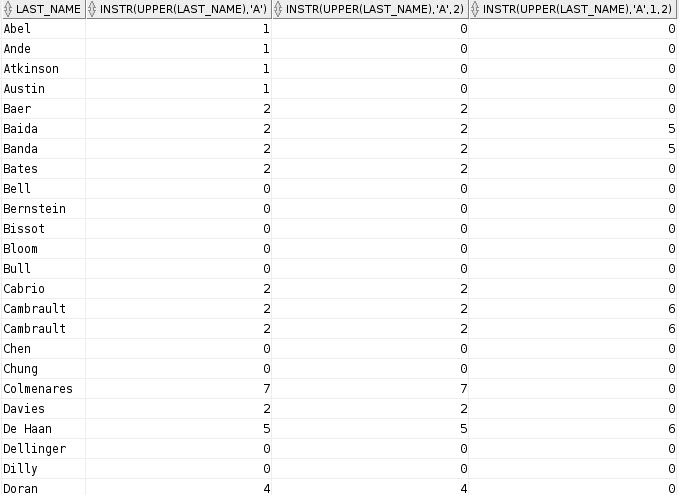
SELECT LAST_NAME,
INSTR( UPPER(LAST_NAME), 'A'), --First occurrence
INSTR( UPPER(LAST_NAME), 'A', 2), --First occurrence starting at second char
INSTR( UPPER(LAST_NAME), 'A', 1, 2) --Second occurrence starting at first char
FROM HR.EMPLOYEES;
Just like CHARINDEX or PATINDEX, it returns the position of the string you’re searching for. The last column is where it’s super interesting to me. I love that kind of flexibility. Here are the results:
![I want all positions!]()
I want all positions!
And just like with SQL Server, you can use substrings and character searching to parse out text between two characters. This is made a bit easier in Oracle by being able to specify the nth occurrence of a character, rather than having to a separate call to CHARINDEX.
SELECT PHONE_NUMBER,
SUBSTR(PHONE_NUMBER, --Phone number
INSTR(PHONE_NUMBER, '.') + 1, --To the first period + 1
INSTR(PHONE_NUMBER, '.', 1, 2) -1 --To the second period - 1
- INSTR(PHONE_NUMBER, '.') ) --Minus the characters prior to the first period
AS "Middle Three"
FROM HR.EMPLOYEES;
And you get that there string parsing magic to just the middle three digits.
![Middling.]()
Middling.
That’s a lot harder when the strings aren’t uniform. We could just just as easily specified the constant positions in SUBSTR. But hey, declaring variables in Oracle is hard work. Seriously. There’s a lot of typing involved. And a colon. It’s weird.
Strung Out
This is as far as I’ve gotten with string manipulation in Oracle. I tried to figure out the stuff that I used to have to do in SQL Server a lot first. That usually makes the rest make more sense down the line. This is one area where I think Oracle clearly wins out. Though there’s a lot of conversation, and rightly so, about if the database is the proper place to do string manipulations like this.
Many people don’t have a choice. SQL either acts as the presentation layer, or the DBAs/developers who have to make these changes only have access to the data at the database level. It’s not rare that someone only knows some form of SQL, either.
Whatever your philosophy on the matter, it’s likely going to keep happening. Oracle makes it much easier to remedy some pretty common issues. One item I didn’t cover is using the LISTAGG function, which is another thing that SQL’s workarounds for are quite hacky, error prone, and involve XML. I can see why it would be a pretty big turn off for more people to have to implement it over a simple function call.
Thanks for reading!
Brent says: Oracle’s string functionality is a good example of why it’s so hard to port apps from one platform to another. It’s not just a matter of mapping functionality exactly, but also finding simpler ways to write the same queries.
Join us in person for The Senior DBA Class or SQL Server Performance Tuning.