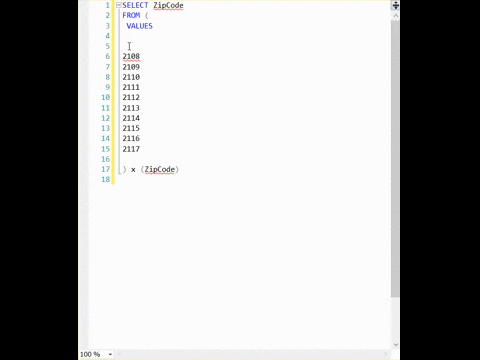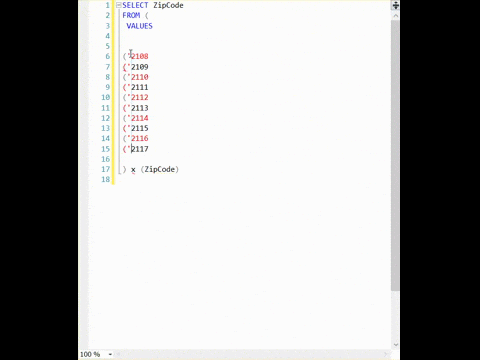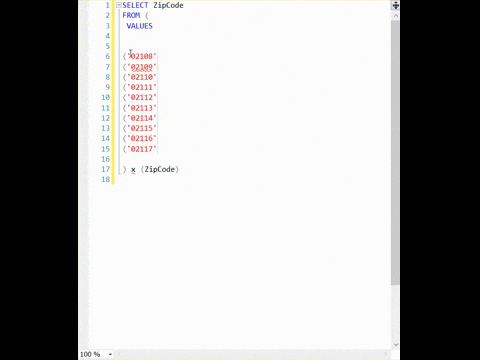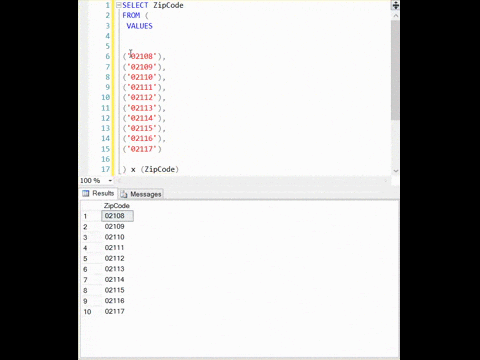
sql server loves unique indexes
Why? Because it’s lazy. Just like you. If you had to spend all day flipping pages around, you’d probably be even lazier. Thank Codd someone figured out how to make a computer do it. There’s some code below, along with some screen shots, but…
TL;DR
SQL is generally pretty happy to get good information about the data it’s holding onto for you. If you know something will be unique, let it know. It will make better plan choices, and certain operations will be supported more efficiently than if you make it futz around looking for repeats in unique data.
There is some impact on inserts and updates as the constraint is checked, but generally it’s negligible, especially when compared to the performance gains you can get from select queries.
So, without further ado!
Q: What was the last thing the Medic said to the Heavy?
A: Demoooooooooo!
We’ll start off by creating four tables. Two with unique clustered indexes, and two with non-unique clustered indexes, that are half the size. I’m just going with simple joins here, since they seem like a pretty approachable subject to most people who are writing queries and creating indexes. I hope.
USE [tempdb]
/*
The drivers
*/
;WITH E1(N) AS (
SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL
SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL
SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL
SELECT NULL ),
E2(N) AS (SELECT NULL FROM E1 a, E1 b, E1 c, E1 d, E1 e, E1 f, E1 g, E1 h, E1 i, E1 j),
Numbers AS (SELECT TOP (1000000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS N FROM E2)
SELECT
ISNULL([N].[N], 0) AS ID,
ISNULL(CONVERT(DATE, DATEADD(SECOND, [N].[N], GETDATE())), '1900-01-01') AS [OrderDate],
ISNULL(SUBSTRING(CONVERT(VARCHAR(255), NEWID()), 0, 9) , 'AAAAAAAA') AS [PO]
INTO UniqueCL
FROM [Numbers] N
ALTER TABLE UniqueCL ADD CONSTRAINT [PK_UniqueCL] PRIMARY KEY CLUSTERED ([ID]) WITH (FILLFACTOR = 100)
;WITH E1(N) AS (
SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL
SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL
SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL
SELECT NULL ),
E2(N) AS (SELECT NULL FROM E1 a, E1 b, E1 c, E1 d, E1 e, E1 f, E1 g, E1 h, E1 i, E1 j),
Numbers AS (SELECT TOP (1000000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS N FROM E2)
SELECT
ISNULL([N].[N], 0) AS ID,
ISNULL(CONVERT(DATE, DATEADD(SECOND, [N].[N], GETDATE())), '1900-01-01') AS [OrderDate],
ISNULL(SUBSTRING(CONVERT(VARCHAR(255), NEWID()), 0, 9) , 'AAAAAAAA') AS [PO]
INTO NonUniqueCL
FROM [Numbers] N
CREATE CLUSTERED INDEX [CLIX_NonUnique] ON dbo.NonUniqueCL ([ID]) WITH (FILLFACTOR = 100)
/*
The joiners
*/
;WITH E1(N) AS (
SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL
SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL
SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL
SELECT NULL ),
E2(N) AS (SELECT NULL FROM E1 a, E1 b, E1 c, E1 d, E1 e, E1 f, E1 g, E1 h, E1 i, E1 j),
Numbers AS (SELECT TOP (1000000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS N FROM E2)
SELECT
ISNULL([N].[N], 0) AS ID,
ISNULL(CONVERT(DATE, DATEADD(SECOND, [N].[N], GETDATE())), '1900-01-01') AS [OrderDate],
ISNULL(SUBSTRING(CONVERT(VARCHAR(255), NEWID()), 0, 9) , 'AAAAAAAA') AS [PO]
INTO UniqueJoin
FROM [Numbers] N
WHERE [N] < 5000001
ALTER TABLE UniqueJoin ADD CONSTRAINT [PK_UniqueJoin] PRIMARY KEY CLUSTERED ([ID], [OrderDate]) WITH (FILLFACTOR = 100)
;WITH E1(N) AS (
SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL
SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL
SELECT NULL UNION ALL SELECT NULL UNION ALL SELECT NULL UNION ALL
SELECT NULL ),
E2(N) AS (SELECT NULL FROM E1 a, E1 b, E1 c, E1 d, E1 e, E1 f, E1 g, E1 h, E1 i, E1 j),
Numbers AS (SELECT TOP (1000000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS N FROM E2)
SELECT
ISNULL([N].[N], 0) AS ID,
ISNULL(CONVERT(DATE, DATEADD(SECOND, [N].[N], GETDATE())), '1900-01-01') AS [OrderDate],
ISNULL(SUBSTRING(CONVERT(VARCHAR(255), NEWID()), 0, 9) , 'AAAAAAAA') AS [PO]
INTO NonUniqueJoin
FROM [Numbers] N
WHERE [N] < 5000001
CREATE CLUSTERED INDEX [CLIX_NonUnique] ON dbo.NonUniqueJoin ([ID], [OrderDate]) WITH (FILLFACTOR = 100)
Now that we have our setup, let’s look at a couple queries. I’ll be returning the results to a variable so we don’t sit around waiting for SSMS to display a bunch of uselessness.
DECLARE @ID BIGINT;
SELECT @ID = [uc].[ID]
FROM [dbo].[UniqueCL] AS [uc]
JOIN [dbo].[UniqueJoin] AS [uj]
ON [uj].[ID] = [uc].[ID]
WHERE [uc].[ID] % 2 = 0
ORDER BY [uc].[ID];
GO
DECLARE @ID BIGINT;
SELECT @ID = [nuc].[ID]
FROM [dbo].[NonUniqueCL] AS [nuc]
JOIN [dbo].[NonUniqueJoin] AS [nuj]
ON [nuj].[ID] = [nuc].[ID]
WHERE [nuc].[ID] % 2 = 0
ORDER BY [nuc].[ID];
GO
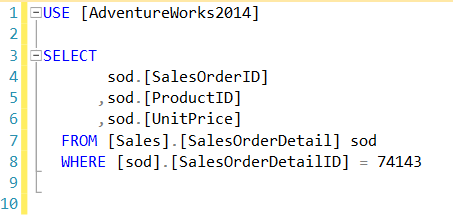
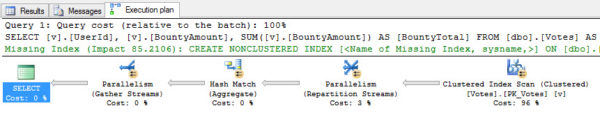
What does SQL do with these?
![Ugly as a river dolphin, that one.]()
Ugly as a river dolphin, that one.
Not only does the query for the unique indexes choose a much nicer merge join, it doesn’t even get considered for parallelilzazation going parallel. The batch cost is about 1/3, and the sort is fully supported.
The query against non-unique tables requires a sizable memory grant, to boot.
Looking at the STATISTICS TIME and IO output, there’s not much difference in logical reads, but you see the non-unique index used all four cores available on my laptop (4 scans, 1 coordinator thread), and there’s a worktable and workfile for the hash join. Overall CPU time is much higher, though there’s only ever about 100ms difference in elapsed time over a number of consecutive runs.
Table 'UniqueJoin'. Scan count 1, logical reads 3969, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'UniqueCL'. Scan count 1, logical reads 3968, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 266 ms, elapsed time = 264 ms.
Table 'NonUniqueCL'. Scan count 5, logical reads 4264, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'NonUniqueJoin'. Scan count 5, logical reads 4264, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1186 ms, elapsed time = 353 ms.
fair fight
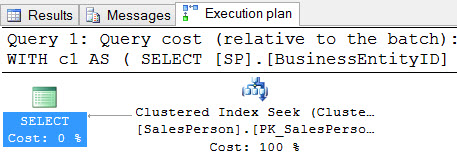
So, obviously going parallel threw some funk on the floor. If we force a MAXDOP of one to the non-unique query, what happens?
![You Get Nothing! You Lose! Good Day, Sir!]()
You Get Nothing! You Lose! Good Day, Sir!
Yep. Same thing, just single threaded this time. The plan looks a little nicer, sure, but now the non-unique part is up to 85% of the batch cost, from, you know, that other number. You’re not gonna make me say it. This is a family-friendly blog.
Going back to TIME and IO, the only noticeable change is in CPU time for the non-unique query. Still needed a memory grant, still has an expensive sort.
Table 'UniqueJoin'. Scan count 1, logical reads 3969, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'UniqueCL'. Scan count 1, logical reads 3968, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 265 ms, elapsed time = 264 ms.
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'NonUniqueJoin'. Scan count 1, logical reads 4218, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'NonUniqueCL'. Scan count 1, logical reads 4218, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 766 ms, elapsed time = 807 ms.
just one index
The nice thing is that a little uniqueness goes a long way. If we join the unique table to the non-unique join table, we end up with nearly identical plans.
![You're such a special flower.]()
You’re such a special flower.
Table 'UniqueJoin'. Scan count 1, logical reads 3969, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'UniqueCL'. Scan count 1, logical reads 3968, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 265 ms, elapsed time = 267 ms.
Table 'NonUniqueJoin'. Scan count 1, logical reads 4218, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'UniqueCL'. Scan count 1, logical reads 3968, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 266 ms, elapsed time = 263 ms.
done and done
So, you made it to the end. Congratulations. I hope your boss didn’t walk by too many times.
By the way, the year is 2050, the Cubs still haven’t won the world series, and a horrible race of extraterrestrials have taken over the Earth and are using humans as slaves to mine gold. Wait, no, that’s something else.
But! Hey! Brains! You have more of them now, if any of this was enlightening to you. If you spaced out and just realized the page stopped scrolling, here’s a recap:
- Unique indexes: SQL likes’em
- You will generally see better plans when the optimizer isn’t concerned with duplicate values
- There’s not a ton of downside to using them where possible
- Even one unique index can make a lot of difference, when joined with a non-unique index.
As an aside, this was all tested on SQL Server 2014. An exercise for Dear Reader; if you have SQL Server 2012, look at the tempdb spills that occur on the sort and hash operations for the non-unique indexes. I’m not including them here because it’s a bit of a detour. It’s probably not the most compelling reason to upgrade, but it’s something to consider — tempdb is way less eager to write to disk these days!
Thanks for reading!
Brent says: I always wanted proof that unique clustered indexes made for better execution plans!