As of this writing, this is all undocumented
I’m super interested in this feature, so that won’t deter me too much. There have been a number of questions since Availability Groups became a thing about how to automate adding new databases. All of the solutions were kind of awkward scripts to backup, restore, join, blah blah blah. This feature aims to make that a thing of the past.
There’s also not a ton of information about how this works, the option hasn’t made it to the GUI, and there may still be some kinks to work out. Some interesting information I’ve come across has been limited to this SAP on SQL blog post, and a Connect item by the Smartest Guy At SanDisk, Jimmy May.
The SAP on SQL Server blog post says that this feature uses the same method as Azure databases to create replicas; opening a direct data link, and Jimmy’s Connect item points to it being a backup and restore behind the scenes. The Extended Events sessions point to it being a backup and restore, so let’s look at those first.
Bring out your XML!
We’re going to need two sessions, because there are two sets of collectors, and it doesn’t make sense to lump them into one XE session. If you look in the GUI, there’s a new category called dbseed, and of course, everything is in the super cool kid debug channel.
![New Extended Event Smell]()
New Extended Event Smell
Quick setup scripts are below.
CREATE EVENT SESSION [DirectSeed] ON SERVER
ADD EVENT sqlserver.hadr_ar_controller_debug(
ACTION(sqlserver.database_id,sqlserver.sql_text,sqlserver.tsql_stack)),
ADD EVENT sqlserver.hadr_automatic_seeding_failure(
ACTION(sqlserver.database_id,sqlserver.sql_text,sqlserver.tsql_stack)),
ADD EVENT sqlserver.hadr_automatic_seeding_start(
ACTION(sqlserver.database_id,sqlserver.sql_text,sqlserver.tsql_stack)),
ADD EVENT sqlserver.hadr_automatic_seeding_state_transition(
ACTION(sqlserver.database_id,sqlserver.sql_text,sqlserver.tsql_stack)),
ADD EVENT sqlserver.hadr_automatic_seeding_success(
ACTION(sqlserver.database_id,sqlserver.sql_text,sqlserver.tsql_stack)),
ADD EVENT sqlserver.hadr_automatic_seeding_timeout(
ACTION(sqlserver.database_id,sqlserver.sql_text,sqlserver.tsql_stack))
ADD TARGET package0.event_file(SET filename=N'C:\XE\DirectSeed.xel',max_rollover_files=(10))
GO
CREATE EVENT SESSION [PhysicalSeed] ON SERVER
ADD EVENT sqlserver.hadr_physical_seeding_backup_state_change(
ACTION(sqlserver.database_id,sqlserver.sql_text,sqlserver.tsql_stack)),
ADD EVENT sqlserver.hadr_physical_seeding_failure(
ACTION(sqlserver.database_id,sqlserver.sql_text,sqlserver.tsql_stack)),
ADD EVENT sqlserver.hadr_physical_seeding_forwarder_state_change(
ACTION(sqlserver.database_id,sqlserver.sql_text,sqlserver.tsql_stack)),
ADD EVENT sqlserver.hadr_physical_seeding_forwarder_target_state_change(
ACTION(sqlserver.database_id,sqlserver.sql_text,sqlserver.tsql_stack)),
ADD EVENT sqlserver.hadr_physical_seeding_progress(
ACTION(sqlserver.database_id,sqlserver.sql_text,sqlserver.tsql_stack)),
ADD EVENT sqlserver.hadr_physical_seeding_restore_state_change(
ACTION(sqlserver.database_id,sqlserver.sql_text,sqlserver.tsql_stack)),
ADD EVENT sqlserver.hadr_physical_seeding_schedule_long_task_failure(
ACTION(sqlserver.database_id,sqlserver.sql_text,sqlserver.tsql_stack)),
ADD EVENT sqlserver.hadr_physical_seeding_submit_callback(
ACTION(sqlserver.database_id,sqlserver.sql_text,sqlserver.tsql_stack))
ADD TARGET package0.event_file(SET filename=N'C:\XE\PhysicalSeed',max_rollover_files=(10))
GO
ALTER EVENT SESSION [DirectSeed] ON SERVER STATE = START
ALTER EVENT SESSION [PhysicalSeed] ON SERVER STATE = START
Since this is so new
I haven’t quite narrowed down which are important and which yield pertinent information yet. Right now I’m grabbing everything. In a prelude to DBA days, I’m adding the StackOverflow database. With some session data flowing in, let’s figure out what we’re looking at. XML shredding fun is up next.
To get information out of the Automatic Seeding session…
IF OBJECT_ID('tempdb..#DirectSeed') IS NOT NULL
DROP TABLE [#DirectSeed];
CREATE TABLE [#DirectSeed]
(
[ID] INT IDENTITY(1, 1)
NOT NULL ,
[EventXML] XML ,
CONSTRAINT [PK_DirectSeed] PRIMARY KEY CLUSTERED ( [ID] )
);
INSERT [#DirectSeed]
( [EventXML] )
SELECT CONVERT(XML, [event_data]) AS [EventXML]
FROM [sys].[fn_xe_file_target_read_file]('C:\XE\DirectSeed*.xel', NULL, NULL, NULL)
CREATE PRIMARY XML INDEX [DirectSeedXML] ON [#DirectSeed]([EventXML]);
CREATE XML INDEX [DirectSeedXMLPath] ON [#DirectSeed]([EventXML])
USING XML INDEX [DirectSeedXML] FOR VALUE;
SELECT
[ds].[EventXML].[value]('(/event/@name)[1]', 'VARCHAR(MAX)') AS [event_name],
[ds].[EventXML].[value]('(/event/@timestamp)[1]', 'DATETIME2(7)') AS [event_time],
[ds].[EventXML].[value]('(/event/data[@name="debug_message"]/value)[1]', 'VARCHAR(8000)') AS [debug_message],
/*hadr_automatic_seeding_state_transition*/
[ds].[EventXML].[value]('(/event/data[@name="previous_state"]/value)[1]', 'VARCHAR(8000)') AS [previous_state],
[ds].[EventXML].[value]('(/event/data[@name="current_state"]/value)[1]', 'VARCHAR(8000)') AS [current_state],
/*hadr_automatic_seeding_start*/
[ds].[EventXML].[value]('(/event/data[@name="operation_attempt_number"]/value)[1]', 'BIGINT') as [operation_attempt_number],
[ds].[EventXML].[value]('(/event/data[@name="ag_id"]/value)[1]', 'VARCHAR(8000)') AS [ag_id],
[ds].[EventXML].[value]('(/event/data[@name="ag_db_id"]/value)[1]', 'VARCHAR(8000)') AS [ag_id],
[ds].[EventXML].[value]('(/event/data[@name="ag_remote_replica_id"]/value)[1]', 'VARCHAR(8000)') AS [ag_remote_replica_id],
/*hadr_automatic_seeding_success*/
[ds].[EventXML].[value]('(/event/data[@name="required_seeding"]/value)[1]', 'VARCHAR(8000)') AS [required_seeding],
/*hadr_automatic_seeding_timeout*/
[ds].[EventXML].[value]('(/event/data[@name="timeout_ms"]/value)[1]', 'BIGINT') as [timeout_ms],
/*hadr_automatic_seeding_failure*/
[ds].[EventXML].[value]('(/event/data[@name="failure_state"]/value)[1]', 'BIGINT') as [failure_state],
[ds].[EventXML].[value]('(/event/data[@name="failure_state_desc"]/value)[1]', 'VARCHAR(8000)') AS [failure_state_desc]
FROM [#DirectSeed] AS [ds]
ORDER BY [ds].[EventXML].[value]('(/event/@timestamp)[1]', 'DATETIME2(7)') DESC
Every time I have to work with XML I want to go to culinary school and become a tattooed cliche on Chopped. Upside? Brent might hire me to be his personal chef. Downside? I’d only be cooking for Ernie.
Here’s a sample of what we get back
I’ve moved the ‘less interesting’ columns off to the right.
![Frenemy.]()
Frenemy.
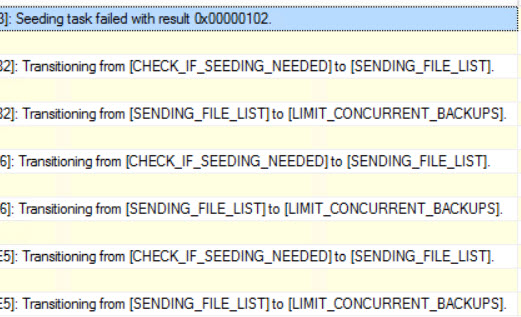
These are my first clues that Jimmy is right about it being a backup and restore. One of the columns says “limit concurrent backups” and, we’re also sending file lists around. Particularly interesting is in the debug column from the hadr_ar_controller_debug item. Here’s pasted text from it.
[HADR] [Secondary] operation on replicas [58BCC44A-12A6-449B-BF33-FAAF9D1A46DD]->[F5302334-B620-4FE2-83A2-399F55AA40EF], database [StackOverflow], remote endpoint [TCP://SQLVM01.darling.com:5022], source operation [55782AB4-5307-47A2-A0D9-3BB29F130F3C]: Transitioning from [LIMIT_CONCURRENT_BACKUPS] to [SEEDING].
[HADR] [Secondary] operation on replicas [58BCC44A-12A6-449B-BF33-FAAF9D1A46DD]->[F5302334-B620-4FE2-83A2-399F55AA40EF], database [StackOverflow], remote endpoint [TCP://SQLVM01.darling.com:5022], source operation [55782AB4-5307-47A2-A0D9-3BB29F130F3C]: Starting streaming restore, DB size [-461504512] bytes, [2] logical files.
[HADR] [Secondary] operation on replicas [58BCC44A-12A6-449B-BF33-FAAF9D1A46DD]->[F5302334-B620-4FE2-83A2-399F55AA40EF], database [StackOverflow], remote endpoint [TCP://SQLVM01.darling.com:5022], source operation [55782AB4-5307-47A2-A0D9-3BB29F130F3C]:
Database file #[0]: LogicalName: [StackOverflow] FileId: [1] FileTypeId: [0]
Database file #[1]: LogicalName: [StackOverflow_log] FileId: [2] FileTypeId: [1]
[HADR] [Secondary] operation on replicas [58BCC44A-12A6-449B-BF33-FAAF9D1A46DD]->[F5302334-B620-4FE2-83A2-399F55AA40EF], database [StackOverflow], remote endpoint [TCP://SQLVM01.darling.com:5022], source operation [55782AB4-5307-47A2-A0D9-3BB29F130F3C]: RESTORE T-SQL String for VDI Client: [RESTORE DATABASE [StackOverflow] FROM VIRTUAL_DEVICE='{AA4C5800-7192-4B77-863B-426246C0CC27}' WITH NORECOVERY, CHECKSUM, REPLACE, BUFFERCOUNT=16, MAXTRANSFERSIZE=2097152, MOVE 'StackOverflow' TO 'E:\SO\StackOverflow.mdf', MOVE 'StackOverflow_log' TO 'E:\SO\StackOverflow_log.ldf']
Hey look, a restore
While I didn’t see an explicit backup command to match, we did pick up data like this:
[HADR] [Primary] operation on replicas [58BCC44A-12A6-449B-BF33-FAAF9D1A46DD]->[571F3967-FB40-4187-BF1E-36A88458C13A], database [StackOverflow], remote endpoint [TCP://SQLVM03.darling.com:5022], source operation [AFB86269-8284-4DB1-95F9-0128EB710825]: Starting streaming backup, DB size [-461504512] bytes, [2] logical files.
A streaming backup! How cute. There’s more evidence in the Physical Seeding session, so let’s look there. Prerequisite XML horrors to follow.
IF OBJECT_ID('tempdb..#PhysicalSeed') IS NOT NULL
DROP TABLE [#PhysicalSeed];
CREATE TABLE [#PhysicalSeed]
(
[ID] INT IDENTITY(1, 1)
NOT NULL ,
[EventXML] XML ,
CONSTRAINT [PK_PhysicalSeed] PRIMARY KEY CLUSTERED ( [ID] )
);
INSERT [#PhysicalSeed]
( [EventXML] )
SELECT CONVERT(XML, [event_data]) AS [EventXML]
FROM [sys].[fn_xe_file_target_read_file]('C:\XE\PhysicalSeed*.xel', NULL, NULL, NULL)
CREATE PRIMARY XML INDEX [PhysicalSeedXML] ON [#PhysicalSeed]([EventXML]);
CREATE XML INDEX [PhysicalSeedXMLPath] ON [#PhysicalSeed]([EventXML])
USING XML INDEX [PhysicalSeedXML] FOR VALUE;
SELECT
[ds].[EventXML].[value]('(/event/@name)[1]', 'VARCHAR(MAX)') AS [event_name],
[ds].[EventXML].[value]('(/event/@timestamp)[1]', 'DATETIME2(7)') AS [event_time],
[ds].[EventXML].[value]('(/event/data[@name="old_state"]/text)[1]', 'VARCHAR(8000)') as [old_state],
[ds].[EventXML].[value]('(/event/data[@name="new_state"]/text)[1]', 'VARCHAR(8000)') as [new_state],
[ds].[EventXML].[value]('(/event/data[@name="seeding_start_time"]/value)[1]', 'DATETIME2(7)') as [seeding_start_time],
[ds].[EventXML].[value]('(/event/data[@name="seeding_end_time"]/value)[1]', 'DATETIME2(7)') as [seeding_end_time],
[ds].[EventXML].[value]('(/event/data[@name="estimated_completion_time"]/value)[1]', 'DATETIME2(7)') as [estimated_completion_time],
[ds].[EventXML].[value]('(/event/data[@name="transferred_size_bytes"]/value)[1]', 'BIGINT') / (1024. * 1024.) as [transferred_size_mb],
[ds].[EventXML].[value]('(/event/data[@name="transfer_rate_bytes_per_second"]/value)[1]', 'BIGINT') / (1024. * 1024.) as [transfer_rate_mb_per_second],
[ds].[EventXML].[value]('(/event/data[@name="database_size_bytes"]/value)[1]', 'BIGINT') / (1024. * 1024.) as [database_size_mb],
[ds].[EventXML].[value]('(/event/data[@name="total_disk_io_wait_time_ms"]/value)[1]', 'BIGINT') as [total_disk_io_wait_time_ms],
[ds].[EventXML].[value]('(/event/data[@name="total_network_wait_time_ms"]/value)[1]', 'BIGINT') as [total_network_wait_time_ms],
[ds].[EventXML].[value]('(/event/data[@name="is_compression_enabled"]/value)[1]', 'VARCHAR(8000)') as [is_compression_enabled],
[ds].[EventXML].[value]('(/event/data[@name="failure_code"]/value)[1]', 'BIGINT') as [failure_code]
FROM [#PhysicalSeed] AS [ds]
ORDER BY [ds].[EventXML].[value]('(/event/@timestamp)[1]', 'DATETIME2(7)') DESC
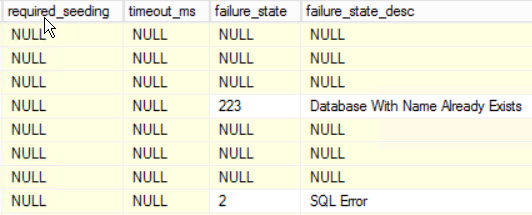
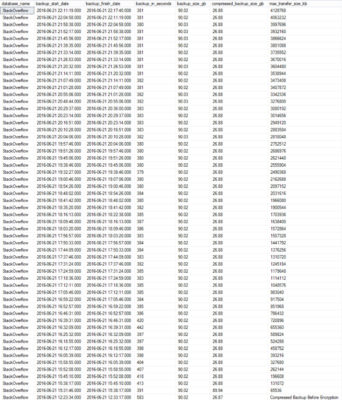
And a sampling of data…
![What an odd estimated completion date.]()
What an odd estimated completion date.
The old state and new state columns also point to backup and restore operations. I assume the completion date points to 1600 BECAUSE THIS IS ABSOLUTE WITCHCRAFT.
![Ooh! Metrics!]()
Ooh! Metrics!
Ignore the smaller sizes at the bottom. I’ve clearly been doing this with a few different databases. The disk IO and network metrics are pretty awesome. Now I have to backtrack a little bit…
The SAP on SQL Server blog post talks about Trace Flag 9567 being used to enable compression. It says that it only has to be enabled on the Primary Replica to work, but even with it turned on on all three of my Replicas, the compression column says false. Perhaps, like parallel redo logs, it hasn’t been implemented yet. I tried both enabling it with DBCC TRACEON, and using it as a startup parameter. Which brings us to the next set of collectors…
DMVs
These are also undocumented, and that kind of sucks. There are two that ‘match’ the XE sessions we have.
[sys].[dm_hadr_physical_seeding_stats]
[sys].[dm_hadr_automatic_seeding]
These can be joined around to other views to get back some alright information. I used these two queries. If you have anything better, feel free to let me know.
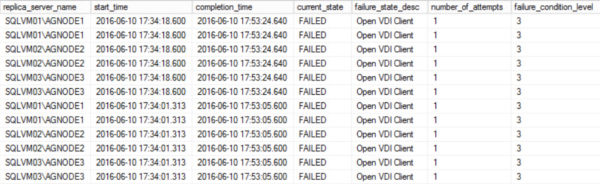
SELECT
ag.name as ag_name,
adc.database_name,
r.replica_server_name,
start_time,
completion_time,
current_state,
failure_state_desc,
number_of_attempts,
failure_condition_level
FROM sys.availability_groups ag
JOIN sys.availability_replicas r ON ag.group_id = r.group_id
JOIN sys.availability_databases_cluster adc on ag.group_id=adc.group_id
JOIN sys.dm_hadr_automatic_seeding AS dhas
ON dhas.ag_id = ag.group_id
LEFT JOIN sys.dm_hadr_physical_seeding_stats AS dhpss
ON adc.database_name = dhpss.local_database_name
WHERE database_name = 'StackOverflow'
ORDER BY completion_time DESC
SELECT
database_name,
transfer_rate_bytes_per_second,
transferred_size_bytes,
database_size_bytes,
start_time_utc,
end_time_utc,
estimate_time_complete_utc,
total_disk_io_wait_time_ms,
total_network_wait_time_ms,
is_compression_enabled
FROM sys.availability_groups ag
JOIN sys.availability_replicas r ON ag.group_id = r.group_id
JOIN sys.availability_databases_cluster adc on ag.group_id=adc.group_id
JOIN sys.dm_hadr_automatic_seeding AS dhas
ON dhas.ag_id = ag.group_id
LEFT JOIN sys.dm_hadr_physical_seeding_stats AS dhpss
ON adc.database_name = dhpss.local_database_name
WHERE database_name = 'StackOverflow'
ORDER BY completion_time DESC
But we get sort of different information back in a couple places. This is part of what makes me wonder how fully formed this feature baby is. The completion estimate is in this century, heck, even this YEAR. The compression column is now a 0. Just a heads up, when I DIDN’T have Trace Flag 9567 on, that column was NULL. Turning it on changed it to 0. Heh. So uh, glad that’s… there.
![I smell like tequila.]()
I smell like tequila.
Oh look, it’s the end
I know I said it before, but I love this new feature. There’s apparently still some stuff to work out, but it’s very promising so far. I’ll post updates as I get more information, but this is about the limit of what I can get without some official documentation.
Thanks for reading!
Wanna shape sp_Blitz and the rest of our scripts? Check out our new Github repository.